在本地搭建 AI 代码助手 Tabby
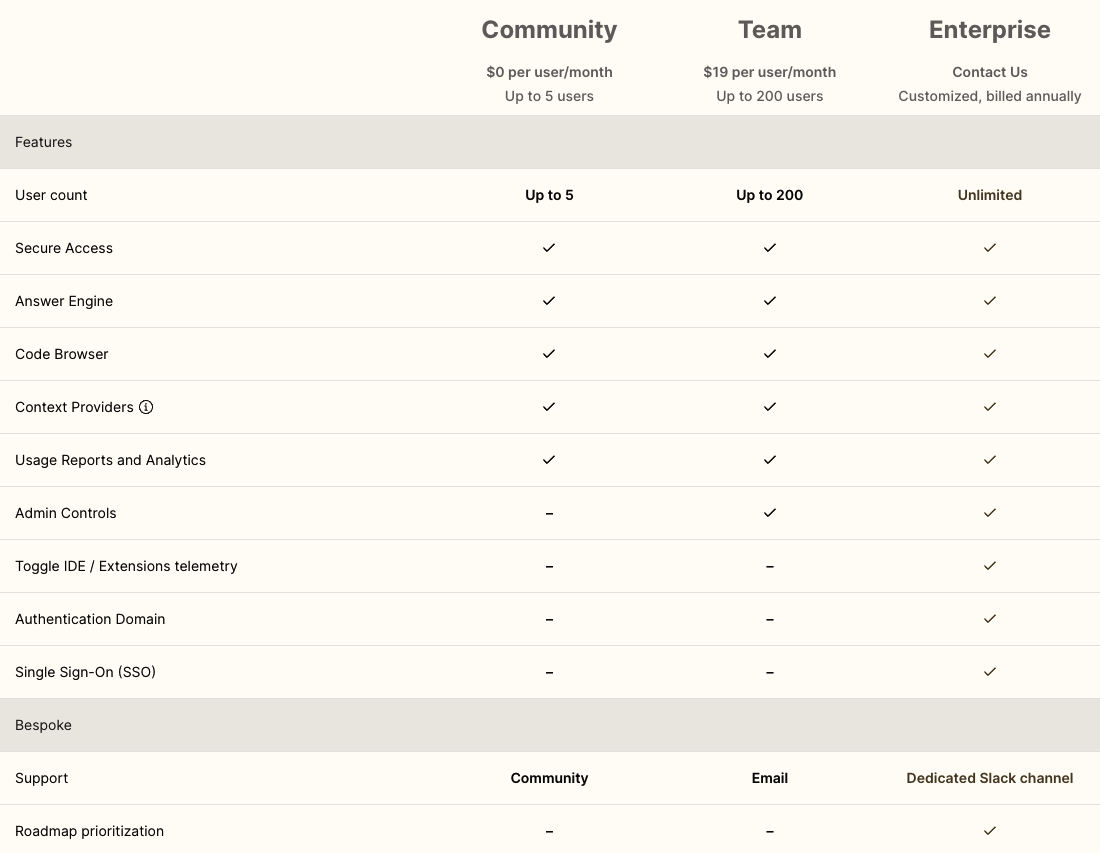
Tabby 是一个开源的AI代码助手,可用于在本地搭建大模型服务。它提供了Web界面,还提供了IDE/编辑器,比如 VS Code插件。Tabby 是用 Rust 编写的,提供了小巧的可执行文件,部署起来非常简单。不过,虽然 Tabby 是开源的,但也是有授权协议的,提供了不同的订阅选项:免费的 Community 授权,以及付费的 Team 和 Enterprise 授权。
搭建本地 Tabby 服务器 🔗
以下以 Linux 服务器为例,介绍如何在本地搭建和使用 Tabby 服务器。
安装 Tabby 🔗
安装 Tabby 本身很简单,下载对应平台的发布包,解压后修改为可执行程序,即可使用。在 Tabby 的官方文件里,提供了 Docker、Linux、Windows、苹果系统等环境下的安装指南。
如果是直接在 Linux 上安装,那么除了下载Tabby本身的程序外,可能还需要安装显卡相关的工具包。比如,CUDA版本需要 nvidia-cuda-toolkit (sudo apt install -y nvidia-cuda-toolkit),可使用 nvcc --version查看 CUDA 的版本;Vulkan 版本需要安装vulkan包(sudo apt install -y libvulkan1)。具体可参见文档。
下载模型和启动服务 🔗
Tabby 程序本身不包含模型,但它可以读取可用的模型列表,然后下载。既可以在运行启动服务子命令(serve)时按需下载模型,也可以使用下载子命令(download)下载模型。
需要注意的是,tabby 程序会读取位于 Github Gist 上的模型列表,但 Gist 在国内(内地)可能无法访问。而 tabby 程序似乎也不支持代理。需要一些特殊方法才可以访问模型列表,比如有人提到这种方法。
Tabby 的启动服务命令示例如下:
# For CPU-only environments
./tabby serve --model StarCoder-1B --chat-model Qwen2-1.5B-Instruct
# For GPU-enabled environments (where DEVICE is cuda or vulkan)
./tabby serve --model StarCoder-1B --chat-model Qwen2-1.5B-Instruct --device $DEVICE
可使用 tabby --help 查看使用说明,比如修改Web服务的端口号等。
如果模型不在本地(位于 ~/.tabby 目录),那么就会去远程下载。tabby 会下载两个模型,一个是代码模型(--model),一个是聊天模型(--chat-model)。使用哪个具体的模型,跟模型本身有关,也跟电脑硬件有关。比如在 NVIDIA GeForce RTX 3070 显卡,若使用 StarCoder-7B 的代码模型,会遇到显存不够的问题(可使用 nvidia-smi 查看显存使用情况):
xxx xx xx:xx:xx dna tabby[956592]: xxxx-xx-xxTxx:xx:xx.552570Z WARN llama_cpp_server::supervisor: crates/llama-cpp-server/src/supervisor.rs:111: <completion>: ggml_backend_cuda_buffer_type_alloc_buffer: allocating 7395.92 MiB on device 0: cudaMalloc failed: out of memory
xxx xx xx:xx:xx dna tabby[956592]: xxxx-xx-xxTxx:xx:xx.552571Z WARN llama_cpp_server::supervisor: crates/llama-cpp-server/src/supervisor.rs:111: <completion>: llama_model_load: error loading model: unable to allocate backend buffer
xxx xx xx:xx:xx dna tabby[956592]: xxxx-xx-xxTxx:xx:xx.552572Z WARN llama_cpp_server::supervisor: crates/llama-cpp-server/src/supervisor.rs:111: <completion>: llama_load_model_from_file: failed to load model
xxx xx xx:xx:xx dna tabby[956592]: xxxx-xx-xxTxx:xx:xx.552573Z WARN llama_cpp_server::supervisor: crates/llama-cpp-server/src/supervisor.rs:111: <completion>: llama_init_from_gpt_params: error: failed to load model '/home/dna/.tabby/models/TabbyML/StarCoder-7B/ggml/model.gguf'
xxx xx xx:xx:xx dna tabby[956592]: xxxx-xx-xxTxx:xx:xx.187538Z WARN llama_cpp_server::supervisor: crates/llama-cpp-server/src/supervisor.rs:99: llama-server <completion> exited with status code -1
不过使用 StarCoder-3B 模型,是可以跑起来的。单人使用的话,响应速度还可以接受。
使用 Tabby 🔗
在浏览器中使用 Tabby 🔗
Tabby 服务启动之后,会在控制台打印访问地址。在浏览器中打开链接即可使用。
在 VS Code中使用 Tabby 🔗
Tabby提供了VS Code插件,可以在编写代码的同时,自动地生成代码补全提示。对于一些简单场景,是可以加速开发的。比如编写 Docker Compose的配置:
结尾 🔗
使用 Tabby 的整体体验是,小巧简单,搭建和使用一气呵成,基本上没有遇到疑难问题。也许是因为模型较小,以及用 Rust编写,响应速度还挺快。值得继续使用。