工业互联网的数据开发实践(一):设备数据的采集
在生产制造中,通常会有两类的系统:IT系统(信息技术系统,即处理数据的硬件和软件的系统)和OT系统(运营技术技术,即控制物理设备运行的系统)。IT系统包含客户管理、产品设计、生产计划、采购、物流、仓储、生产执行、设备管理、财务、人员等信息系统(也可以说是广义的ERP)。而OT系统主要指管理生产车间的硬件和软件,包括PLC、SCADA、网关、机器人等等,这些系统用于控制设备,同时记录生产过程中的设备状态、事件等数据,比如某个设备某个部位的温度变化、开关机状态等。
最近时髦的话语是“工业互联网”。网络上对工业互联网有诸多抽象的定义,比如“工业互联网涵盖了工业物联网的技术部分,工业互联网是要实现人、机、物的全面互联,追求的是业务数字化;而工业物联网强调的是物与物的连接,追求的是生产自动化”。
如果通俗和具象一点儿,可以简单地认为,在工业互联网之前,生产执行中涉及两个系统:IT系统记录每个生产工单的状态和操作事件,OT系统用来控制生产设备。OT系统收集了生产设备的数据,但是这些数据并没有跟业务活动强关联。比如虽然OT系统采集了某个时间段里某个设备的用电能耗,但是这些数据点并没有关联到某个具体的生产工单,那么就难以准确地分析不同工单的能耗情况。于是,也就无法与生产执行之前的活动,比如排产、计划、销售、财务等记录自动地关联)。再比如,生产设备可能同时生产多个工单,但是数据点无法区别不同的工单。如果近距离走进生产车间,很可能会发现,生产设备旁边有两台电脑:一台与IT系统连接;一台与生产设备连接。IT与OT的割裂,导致企业难以将业务流程与生产工艺进行统一的优化。因此,业界提出了将网络信息技术与制造业深度融合的工业互联网的概念,以期望它为生产决策提供科学依据,从而提高生产效率和质量。
在工业互联网的宏观命题之下,制造业对大数据和人工智能寄予厚望,期望能帮助企业完成数字化转型,实现可持续的高质量发展。本系列文章将结合真实的用户案例,探索工业互联网的数据开发实践。
本文作为《工业互联网的数据开发实践》系列的第一篇,探讨生产设备的数据采集,即OT系统的数据采集。这里考虑三个因素:
- 数据管道
- 数据模型
- 数据存储
然后给出几个技术实现方案。
数据管道:协议转换器 🔗
在构建工业互联网之前,得先构建物联网,将生产设备连接起来,将数据收集起来。然后再与IT系统集成。在互联互通的技术上,在靠近生产的OT系统通常使用工业标准的架构和协议,比如Modbus、OPCUA等;而在靠近互联网一侧,通常使用物联网技术,比如MQTT,以满足低带宽和不可靠的网络条件。因此在技术上来说,需要修建一条协议转换的桥梁和公路,将设备数据进行转换,然后传输到互联网,落盘存储。
数据模型:物模型 🔗
在修好了数据传输的桥梁和公路之后,就要考虑如何存储这些数据。通常来说,一个设备会有多个点位,每个点位输出一个值。它可能代表设备的某个部位的状态、变化的数值、或者某种事件之一。每个点位的数据类型不同、变化频率不同,产生的数据量也不同。从数据的使用场景来看,有时候关注的是某个点位的数据,但更多的时候,可能关注的是这个设备的多个点位的数据,然后进行关联分析。因此采集到的最原始的点位数据,可能并不适合后期理解和使用。
因此在考虑存储大量数据的介质之外,首先考虑如何数据模型。其中有一种方法是构建“物模型”。此时此刻,ChatGPT给出的物模型的定义是:“在物联网(物联网)领域,物模型(物联网物模型)是指描述和表示物理世界中物体、设备或实体的信息模型。物模型通过定义各种属性、状态、行为和关系,提供了对物体在网络中的抽象描述。”
在阿里云物联网平台的 文档 中,物模型是这样定义的:“物模型是物理空间中的实体(如传感器、车载装置、楼宇、工厂等)在云端的数字化表示,从属性、服务和事件三个维度,分别描述了该实体是什么、能做什么、可以对外提供哪些信息。 定义了物模型的这三个维度,即完成了产品功能的定义。 用于描述设备运行时具体信息和状态。”
按照物模型的思路,建模的最小单位是物理实体(比如某个设备),而不是设备中的每个点位(对应到设备的每个属性等)。这种层级化的组织方式,让数据采集、管理和消费更加易用。
数据存储:时序数据库 🔗
虽然可以将采集到的数据存储到任何的存储介质,比如文件系统、对象存储、关系型数据库、文档数据库,甚至内存中,但物联网通常涉及的都是时间相关的数据,而时间序列数据库(时序数据库,简称TSDB)是专门设计用于高效存储和查询时间序列数据的数据库,提供了针对时间范围的高性能查询。因此时序数据库可以作为存储和分析设备数据的首选方式。对于复杂场景,可以根据具体的应用场景,再进行二次加工和存储。
开源的时序数据库有InfluxDB、Apache IoTDB等。一些云平台也提供了时序数据库(比如阿里云的Lindorm的时序引擎)。
技术实现方案 🔗
常年从事IT系统开发的软件工程师对工业软件对是比较陌生的,可能会听到很多名词,比如SCADA、OPCUA、Modbus 等;而在制造业的软件开发人员,尤其是中国传统制造业中,很多地处远离大城市的工业区,缺乏软件人才,难以接触较为先进的软件开发技术。但是,在这些高深莫测的英文缩写背后,大部分都是相对成熟的技术。所以,不要觉得难度有多高,大胆假设小心求证,找到不同利益相关者的共同语言,聚焦到真正的关注点,找到合适的技术解决方案。
从技术提供商来说,可以有商业产品提供商和开源技术。企业根据自身的战略和历史包袱,综合不同方案的性价比,选择最优的技术方案。
方案一:物联网产品+物联网平台 🔗
市面上的一些智能解决方案中,除了带传感器的设备,还提供了互联网网关,可以将设备的实时数据转发到互联网平台。然后就可以在物联网平台构建物模型,并进行数据存储。
比如使用如下的数据链路,物联网网关充当了协议转换器,在它上面上配置物联网平台即可。这类网关可能还包括了发送重试、本地的短期存储等能力。国内的一些公有云提供了物联网平台,比如阿里云的物联网平台,核心是MQTT服务器。从直觉上来说,国内的智能解决方案与阿里云平台的兼容性应该是不错的。
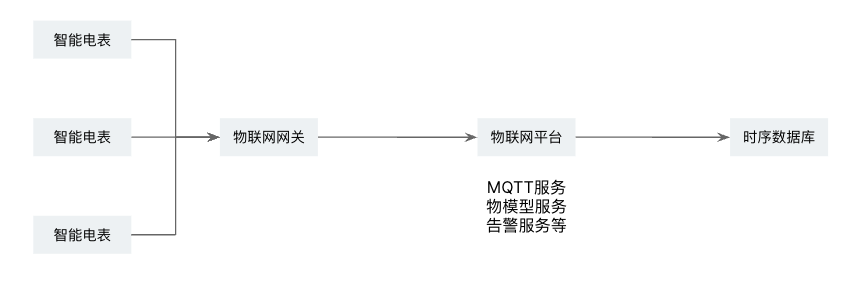
物联网平台通常也提供了将物联网数据流转到其他介质的能力。这种数据流转本质上可以是一个MQTT的客户端,它从物联网平台MQTT服务器订阅数据,然后发送到目的地。这种流转可能需要进行一些编码工作。比如阿里云的物联网平台提供了将数据存储到Lindorm时序引擎数据库的能力,此时需要使用裁剪版本的Javascript语言编写数据映射。
小贴士:如果使用阿里云的物联网平台,当本地机房(物联网网关所在的网络)与阿里云的物联网平台是通过VPN连接的,那么需要在阿里云的VPC上创建一个四层代理(比如Nginx四层代理),本地互联网网关通过这个代理才能访问物联网平台。
方案二:开源软件+物联网平台 🔗
在某些生产线中,可能并没有“物联网网关”,但是设备提供了工业数据交换协议接口,比如OPCUA、modbus。那么就需要采购(或者采用)单独的协议转换器。
如果采用开源软件,那么Telegraf是一个不错的选择。它是一个采集系统指标、传感器数据的服务代理,由Go语言编写,最终被编译成一个可执行文件。它支持众多的数据源、数据转换和数据输出插件,用户只需要编写配置文件,然后使用可执行文件传入配置文件路径即可运行。在真实场景的实施中,还需要对Telegraf进程本身进行服务监控、报警等。
如下所示,SCADA是在生产制造中的数据采集与监视控制系统。从数据交换的协议来看,它就是一个OPCUA协议的数据源。Telegraf 提供了两种采集方式。这两种方式都需要配置设备的每个点位。企业根据具体的使用场景选择合适的采集方式。
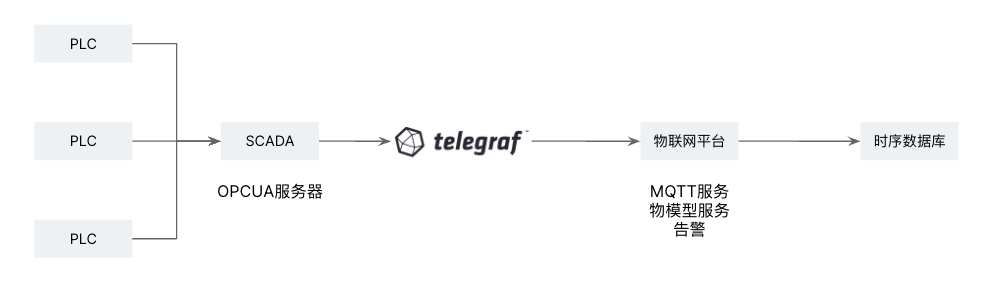
使用 opcua_listener 插件订阅数据变化 🔗
opcua_listener 插件采用订阅模式读取OPC UA服务器的数据。对于配置的点位,在数据发生变化时,telegraf程序会采集到数据。注意,每个点位的数值变化频率是不同的,因此采集到的数据点的时间大都是不同的时刻。最终的输出是每个点位的数值。此时如果一个设备有多个点位,那么很难方便地查询某个时间,所有点位的数据值,所以可能需要后期进一步进行时间戳对齐等处理。
使用 opcua 插件周期性地轮询数据点位 🔗
opcua 插件可以轮询数据点位,比如每隔1秒采集所配置的所有点位数据。这样的采集数据的时刻,会得到所有点位当前数值。这种的好处是,采集到的数据已经在时间戳上对齐了。于是可以将同一个设备的所有点位在同一时刻的数值合并成一条数据。这样可以很方便地查询在某个时刻,这个设备的所有点位的数据。
但这种方式也有弊端。比如某些点位的数值变化频率很高,可能在1秒之内变化了多次,此时只能采集到一次;如果增加采集频率,又可能对SCADA服务器带来影响。而有些点位数据的变化频率很低,比如几个小时才变化一次,或者晚上设备休息时的数据没有任何意义,但依然会保存起来,导致浪费存储空间。
阿里云物联网平台的MQTT Topic是以斜杠(/)开头的(比如上报数据的Topic为 /sys/productKey/deviceId/thing/event/property/post )。但以斜杠开头会引起歧义,因此在业界不被建议。所以在使用开源方案时,可能会出现兼容性问题。好消息是在 Telegraf 的1.29.3 版本已经修复了这个问题。
方案三:开源软件 🔗
如果企业并没有打算使用云服务,也没有采购私有云的计划,同时有足够扎实的软件运维能力(甚至定制开发的能力),那么可以考虑采用纯粹的开源软件方案。或者在采集到数据后,在本地(即边缘侧)存储数据,然后进行加工处理(比如降频、对齐时间戳)后,再流转到云平台。
或者,企业暂时没有对物联网平台(比如数字孪生、数据下发等)的强烈需求,可以直接将数据持久化到时序数据库中,简化架构。Telegraf 提供了将数据写入 InfluxDB、Apache IoTDB等时序引擎的插件。如下所示:
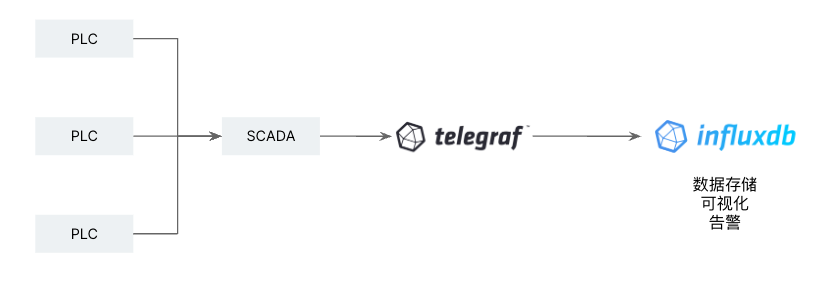
如果想使用阿里云的Lindorm时序引擎作为数据库,那么可以使用HTTP输出插件并以influx格式写入Lindorm。需要注意的是,目前Lindorm提供了公网和VPC地址,但提供的是HTTP接口+IP白名单限制,而不是HTTPS接口,所以是没有启用传输加密的,在使用时需要评估。
结尾 🔗
本文介绍了设备数据采集的考量因素和技术方案。有了持久化的数据之后,就可以根据应用场景进行盘点、探索和使用。